Directed evolution can identify the useful molecules in a sea of useless ones, and select only the useful molecules for replication. However, the process can also fine-tune those molecules by incorporating a surprising tool: mutation.
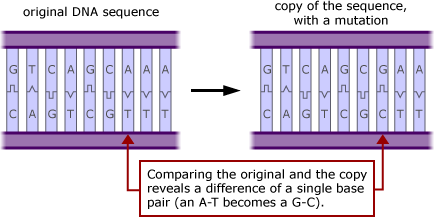
A mutation is simply a change in the sequence of a DNA molecule, but mutations have a reputation for being harmful — for causing cancer, birth defects, and the like. How does the process of mutation help evolutionary engineers evolve useful molecules? The key is that although random mutations usually lead to either no effect or a detrimental one, selection can single out and preserve the occasional mutation that improves the function of the original molecule. It works like this:
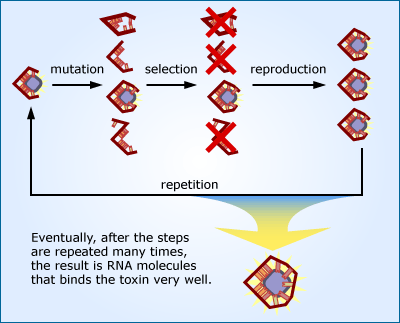
1. Initial population: Begin with a pool of RNA that does a particular job, such as binding to a toxin. The molecules are very similar to one another and bind the toxin equally well. This population has low genetic variation.
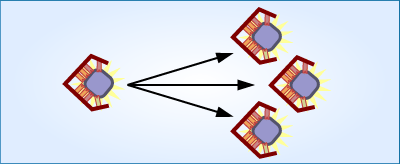
2. Mutation: Produce a mutated pool of RNAs. This increases the genetic variation of the RNA pool. Most of the mutated RNAs don’t bind the toxin as well as they originally did — however, a few just happened to have sustained a mutation that improved their function.

3. Selection: Test the pool of RNAs for ability to bind the toxin, and select only those that perform the best. This selected pool of RNA performs better, on average, than the original pool.

4. Reproduction: Copy the selected RNAs.
5. Repetition: Repeat the process of mutation, selection, and reproduction. With each repetition, the pool of RNAs evolves and binds the toxin a little better.
In this way, selection (in this case, artificial selection) can transform the process of random mutation into one that leads to evolution in a particular direction.